Artifact Submission Lifecycle
- Initial Submission: Submit the artifact to the HotCRP site that corresponds to the cycle your paper was accepted in (spring/summer) before submission deadline. For example, if you submitted in the spring and was accepted in the summer cycle, you would submit to the summer AEC HotCRP site.
- Kick-the-Tires: The reviewers will setup the artifact and run the ‘basic test’ command specified in the artifact appendix to validate the artifact works. This setup task will be completed before the kick-the-tires deadline. At this point, the reviewers report if they succeeded in getting the artifact working.
- Troubleshooting: After the kick-the-tires deadline, the reviewers will anonymously correspond with authors through the HotCRP site to troubleshoot the artifact in the event it doesn’t work.
- Artifact Evaluation: At the review deadline, the reviewers release their reviews and score the artifact’s availability/reproducibility/basic functionality.
- Camera-Ready Submission: At the paper camera-ready deadline, the authors incorporate a 2-page version of the artifact appendix into their camera-ready with DOI links for the artifact materials (if given the available badge). Either the authors or ACM will attach the awarded badges.
Submitting your Artifact
Submit your artifact to the AEC HotCRP site that corresponds to the cycle your paper was accepted in (spring / summer).
The Artifact Title and Paper Identifier
The submission page will request some basic information about your artifact.
- Title: Please use your ASPLOS paper title as the artifact title.
- Submission # and Phase: Specify the paper # of the main paper and the cycle (spring/summer) it was submitted to.
- Acceptance Phase: Specify the phase (spring/summer/fall) the paper was accepted in. This should match the phase of the HotCRP AEC submission site.
The Artifact Abstract
Briefly and informally describe your artifact including minimal hardware and software requirements, how it supports your paper, how it can be validated, and what is the expected result. It will be used to select appropriate reviewers. It will also help readers understand what was evaluated and how.
Artifact Topics
The HotCRP submission site will give you the option of selecting topics related to your submission. Mark off any relevant areas (options under topics heading) and relevant requirements (options under requirements heading) for your artifact. We will use the marked areas to match reviewers to artifacts and the marked requirements to quickly filter out potential reviewers that lack the necessary hardware/software.
Artifact Appendix
Please submit your paper with an artifact appendix attached to the end of the document. Please refer to the sections below for information on how to structure your appendix. The reviewers need both the full paper and the appendix to reproduce your results.
Artifact Appendix Download Link
Download the ae.tex template for the artifact appendix here. You may also format the artifact appendix yourself, provided it contains all the relevent sections in the ae.tex file.
Artifact Appendix Overview
Next, we describe what each section in the artifact appendix should cover. Please read this carefully to make sure that the artifact appendix provides enough information to reproduce the results in the paper.
Checklist [Obligatory]
Fill in whatever is applicable with some informal keywords and remove all items that are unrelated to the artifacts. Please consider questions below just as informal hints that will help reviewers figure out what to watch out for when evaluating the artifact.
Algorithm: Are you presenting a new algorithm?
Program: Which benchmarks do you use (PARSEC ARM real workloads, NAS, EEMBC, SPLASH, Rodinia, LINPACK, HPCG, MiBench, SPEC, cTuning, etc)? Are they included or should they be downloaded? Which version? Are they public or private? If they are private, is there a public analog to evaluate your artifact? What is the approximate size?
Compilation: Do you require a specific compiler? Public/private? Is it included? Which version?
Transformations: Do you require a program transformation tool (source-to-source, binary-to-binary, compiler pass, etc)? Public/private? Is it included? Which version?
Binary: Are binaries included? OS-specific? Which version?
Model: Do you use specific models (ImageNet, AlexNet, MobileNets)? Are they included? If not, how to download and install? What is their approximate size?
Data set: Do you use specific data sets? Are they included? If not, how to download and install? What is their approximate size?
Run-time environment: Is your artifact OS-specific (Linux, Windows, MacOS, Android, etc) ? Which version? Which are the main software dependencies (JIT, libs, run-time adaptation frameworks, etc); Do you need root access?
Hardware: Do you need specific hardware (supercomputer, architecture simulator, CPU, GPU, neural network accelerator, FPGA) or specific features (hardware counters to measure power consumption, SUDO access to CPU/GPU frequency, etc)? Are they publicly available?
Run-time state: Is your artifact sensitive to run-time state (cold/hot cache, network/cache contentions, etc.)
Execution: Any specific conditions should be met during experiments (sole user, process pinning, profiling, adaptation, etc)? How long will it approximately run?
Metrics: Which metrics are reported (execution time, inference per second, Top1 accuracy, static and dynamic energy consumption, etc) – particularly important for multi-objective benchmarking, optimization and co-design (see ACM ReQuEST ML/SW/HW co-design tournaments).
Output: What is your output (console, file, table, graph) and what is your result (exact output, numerical results, measured characteristics, etc)? Is expected result included?
Experiments: How to prepare experiments and replicate/reproduce results (OS scripts, manual steps by user, IPython/Jupyter notebook, automated workflows, etc)? Do not forget to mention the maximum allowable variation of empirical results!
How much disk space required (approximately)?: This can help evaluators and end-users to find appropriate resources.
How much time is needed to prepare workflow (approximately)?: This can help evaluators and end-users to estimate resources needed to evaluate your artifact.
How much time is needed to complete experiments (approximately)?: This can help evaluators and end-users to estimate resources needed to evaluate your artifact.
Publicly available?: Will your artifact be publicly available? If yes, we may spend an extra effort to help you with the documentation.
Code licenses (if publicly available)?: If your workflows and artifacts will be publicly available, please provide information about licenses. This will help the community to reuse your components.
Data licenses (if publicly available)?: If your workflows and artifacts will be publicly available, please provide information about licenses. This will help the community to reuse your components.
Workflow frameworks used?: Did authors use any workflow framework which can automate and customize experiments?
Archived?: Note that the author-created artifacts relevant to this paper will receive the ACM “artifact available” badge *only if* they have been placed on a publicly accessible archival repository such as Zenodo, FigShare or Dryad. A DOI will be then assigned to their artifacts and must be provided here! Personal web pages, Google Drive, GitHub, GitLab and BitBucket are not accepted for this badge. Authors can provide this link at the end of the evaluation.
How to access [Obligatory]
Describe how reviewers can access your artifact. Here are some common access procedures:
- Clone repository from GitHub, GitLab, BitBucket or any similar service.
- Download package from a public website.
- Download package from a private website. Because the review process is single-blind, you can provide the full link in the appendix.
- Access artifact via private machine with pre-installed software. This is only acceptable when access to rare hardware is required or proprietary software is used – you will need to send information and credentials to access your machine to the AE chairs.
Please describe approximate disk space required after unpacking your artifact (to avoid surprises when artifact requires 20GB of free space). We do not have a strict limit but strongly suggest to limit the space to several GB and avoid including unnecessary software packages to your VM images.
Dependencies [Obligatory]
First the artifact appendix should provide some basic information to help the user assess if their system can run the the supplied artifact. This section outlines any hardware and software dependences and any datasets and models that are used in the evaluation.
- Hardware dependencies [Optional]: Describe any relevant hardware requirements. This may describe specialized hardware requirements, specialized resource requirements for general purpose hardware, or specialized measurement equipment (e.g., Oscilloscope, Digital Analyzer).
- Examples: CUDA-enabled NVidia GPUs, Xilinx Virtex 7 FPGA, Machine with > 32 cores and > 128 GB memory
- Hint: If you require specialized, commercially available hardware (e.g., GPUs & FPGAs), it may be helpful to identify several potential devices your system can be evaluated on, as we may have trouble finding a reviewer who has your exact hardware model.
- Hint: We do not yet have a funding mechanism for providing AWS credits to reviewers, so we recommend avoiding AWS nodes as a hardware target if at all possible.
- Software dependencies [Optional]: Describe any specific OS and software packages required to evaluate your artifact. This is particularly important if you share your source code and it must be compiled or if you rely on some proprietary software that you can not include to your package. In such case, we strongly suggest you to describe how to obtain and to install all third-party software, data sets and models.
- Examples: Xilinx Vivado, Cadence Virtuoso, Tensorflow, BLAS
- Datasets [Optional]: Describe any datasets that the artifact depends on. If third-party data sets are not included in your packages (for example, they are very large or proprietary), please provide details about how to download and install them. In case of proprietary data sets, we suggest you provide reviewers a public alternative subset for evaluation.
- Examples: Machine Learning Datasets, Datacenter Data, SPEC Benchmark Suites, Fabrication Facility Data, Raw Measurement Data (from Oscilloscope, for example)
- Models [Optional]: Describe any models that the artifact depends on. If third-party models are not included in your packages (for example, they are very large or proprietary), please provide details about how to download and install them.
- Examples: Proprietary process design kits (PDKs), AlexNet, ImageNet
Frequently Asked Questions
Do I have to open source my software artifacts?
No, it is not strictly necessary and you can provide your software artifact as a binary. However, in case of problems, reviewers may not be able to fix it and will likely give you a negative score.
Is Artifact evaluation blind or double-blind?
AE is a single-blind process, i.e. authors’ names are known to the evaluators (there is no need to hide them since papers are accepted), but names of evaluators are not known to authors. AE chairs are usually used as a proxy between authors and evaluators in case of questions and problems.
How to pack artifacts?
We do not have strict requirements at this stage. You can pack your artifacts simply in a tar ball, zip file, Virtual Machine or Docker image. You can also share artifacts via public services including GitHub, GitLab and BitBucket. Please see our submission guide for more details.
Is it possible to provide a remote access to a machine with pre-installed artifacts?
Only in exceptional cases, i.e. when rare hardware or proprietary software/hardware/benchmarks are required, or VM image is too large or when you are not authorized to move artifacts outside your organization. In such case, you will need to send the access information to the AE chairs via private email or SMS. They will then pass this information to the evaluators.
Can I share commercial benchmarks or software with evaluators?
Please check the license of your benchmarks, data sets and software. In case of any doubts, try to find a free alternative. In fact, we strongly suggest you provide a small subset of free benchmarks and data sets to simplify the evaluation process.
Can I engage with the community to evaluate my artifacts?
Based on the community feedback, we allow open evaluation to let the community validate artifacts which are publicly available at GitHub, GitLab, BitBuckets, etc, report issues and help the authors to fix them. Note, that in the end, these artifacts still go through traditional evaluation process via the AE committee. We successfully validated at ADAPT’16 and CGO/PPoPP’17!
How to automate, customize and port experiments?
From our past experience reproducing research papers, the major difficulty that evaluators face is the lack of a common and portable workflow framework in ML and systems research. This means that each year they have to learn some ad-hoc scripts and formats in nearly all artifacts without even reusing such knowledge the following year. Things get even worse if an evaluator would like to validate experiments using a different compiler, tool, library, data set, operating systems or hardware rather than just reproducing quickly outdated results using VM and Docker images – our experience shows that most of the submitted scripts are not easy to change, customize or adapt to other platform.
That is why we collaborate with the community and ACM to develop a common experimental framework (CK). You can see how CK workflows helped to automate, crowdsource and visualize experiments in the 1st ACM ReQuEST-ASPLOS’18 tournament to co-design Pareto-efficient software/hardware stack for deep learning: CK workflows, ACM proceedings, report and public dashboards with reproducible results. You can find reproduced papers with portable CK workflows and reusable components using the cKnowledge.io portal. Please, follow this guide if you want to convert your artifacts and workflows to the CK format.
Do I have to make my artifacts public if they pass evaluation?
No, you don’t have to and it may be impossible in the case of commercial artifacts. Nevertheless, we encourage you to make your artifacts publicly available upon publication, for example, by including them in a permanent repository (required to receive the “artifact available” badge) to support open science as outlined in our vision.
Furthermore, if you make your artifacts publicly available at the time of submission, you may profit from the “public review” option, where you are engaged with the community to discuss, evaluate and use your software. See such examples here (search for “public evaluation”).
How to report and compare empirical results?
First of all, you should undoubtedly run empirical experiments more than once (we still encounter many cases where researchers measure execution time only once). and perform statistical analysis. There is no universal recipe how many times you should repeat your empirical experiment since it heavily depends on the type of your experiments, platform and environment. You should then analyze the distribution of execution times as shown in the figure below:
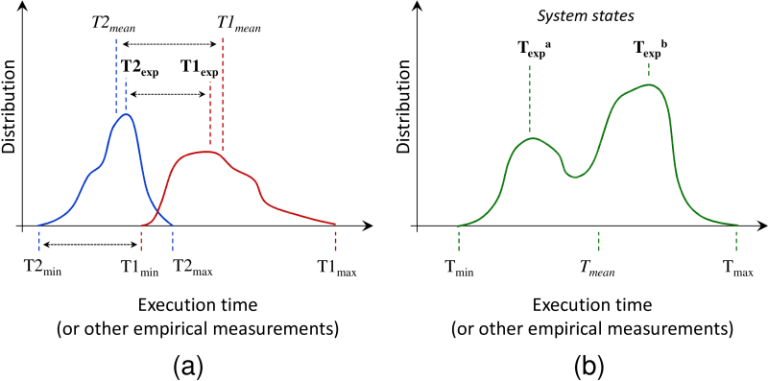
If you have more than one expected value (b), it means that you have several run-time states in your system (such as adaptive frequency scaling) and you can not use average and reliably compare empirical results. However, if there is only one expected value for a given experiment (a), then you can use it to compare multiple experiments. This is particularly useful when running experiments across different platforms from different users as described in this article.
You should also report the variation of empirical results together with all expected values. Furthermore, we strongly suggest you to pre-record results from your platform and provide a script to automatically compare new results with the pre-recorded ones. Otherwise, evaluators can spend considerable amount of time digging out and validating results from “stdout”. For example, see how new results are visualized and compared against the pre-recorded ones using some dashboard in the CGO’17 artifact.
How to deal with numerical accuracy and instability?
If the accuracy of your results depends on a given machine, environment and optimizations (for example, when optimizing BLAS, DNN, etc), you should provide a script to automatically report unexpected loss in accuracy above provided threshold as well as any numerical instability.
How to validate models or algorithm scalability?
If you present a novel parallel algorithm or some predictive model which should scale across a number of cores/processors/nodes, we suggest you to provide an experimental workflow that could automatically detect the topology of a user machine, validate your models or algorithm scalability, and report any unexpected behavior.
Is there any page limit for my Artifact Evaluation Appendix?
There is no limit for the AE Appendix at the time of the submission for Artifact Evaluation.
However, there is currently a 2 page limit for the AE Appendix in the camera-ready CGO, PPoPP, ASPLOS and MLSys papers. There is no page limit for the AE Appendix in the camera-ready SC paper. We also expect that there will be no page limits for AE Appendices in the journals willing to participate in the AE initiative.